Por Que Avaliar seu RAG?
Um RAG em producao precisa de metricas. Sem avaliacao, voce nao sabe se esta retornando chunks relevantes, se as respostas sao fundamentadas nos documentos, ou se os usuarios estao satisfeitos.
Sem Avaliacao
"Parece que funciona" nao e metrica
Avaliacao Manual
Nao escala, subjetiva, inconsistente
Avaliacao Automatica
Metricas objetivas, continua, escalavel
Metricas Principais
Relevance Score
Mede se os chunks retornados sao relevantes para a query. Use um LLM para avaliar cada chunk de 0-10.
Query: {{ query }}
Chunk: {{ chunk }}
Output: { score: number, reason: string }"
Groundedness Score
Verifica se a resposta e fundamentada nos chunks. Detecta "alucinacoes" onde o LLM inventa informacoes.
Context: {{ chunks }}
Answer: {{ response }}
Output: { grounded: boolean, ungrounded_claims: [] }"
Answer Accuracy
Compara resposta com ground truth (quando disponivel). Util para FAQs e perguntas com respostas conhecidas.
- Exact Match: response == expected
- BLEU Score: n-gram overlap
- Semantic Similarity: embedding cosine
User Satisfaction
Feedback direto do usuario: thumbs up/down, ratings, comentarios.
- Was this helpful? [Yes/No]
- Rate 1-5 stars
- What was missing?
Human-in-the-Loop (HITL)
Feedback Loop
1. Coleta de Feedback
Usuario indica se resposta foi util. Armazena: query, response, chunks, rating.
2. Analise de Padroes
Identifica queries com baixo rating. Agrupa por topico ou tipo de erro.
3. Ajuste do Sistema
Adiciona exemplos ao prompt, ajusta chunking, melhora retrieval.
RLHF (Reinforcement Learning)
Use feedback para treinar um reward model ou ajustar prompts:
- Good responses (rating >= 4)
- Bad responses (rating <= 2)
Train reward model or
Fine-tune prompt examples
Pipeline de Avaliacao no N8N
Query + Response
LLM Evaluator
Dashboard
Workflow de Avaliacao:
2. Query logs table for unscored responses
3. For each: call LLM with evaluation prompt
4. Store scores in eval_results table
5. Alert if avg_score < threshold
6. Weekly report to Slack/Email
Metricas para Dashboard
Avg Relevance Score
Groundedness Rate
Avg User Rating
Avg Response Time
Workflow para Download
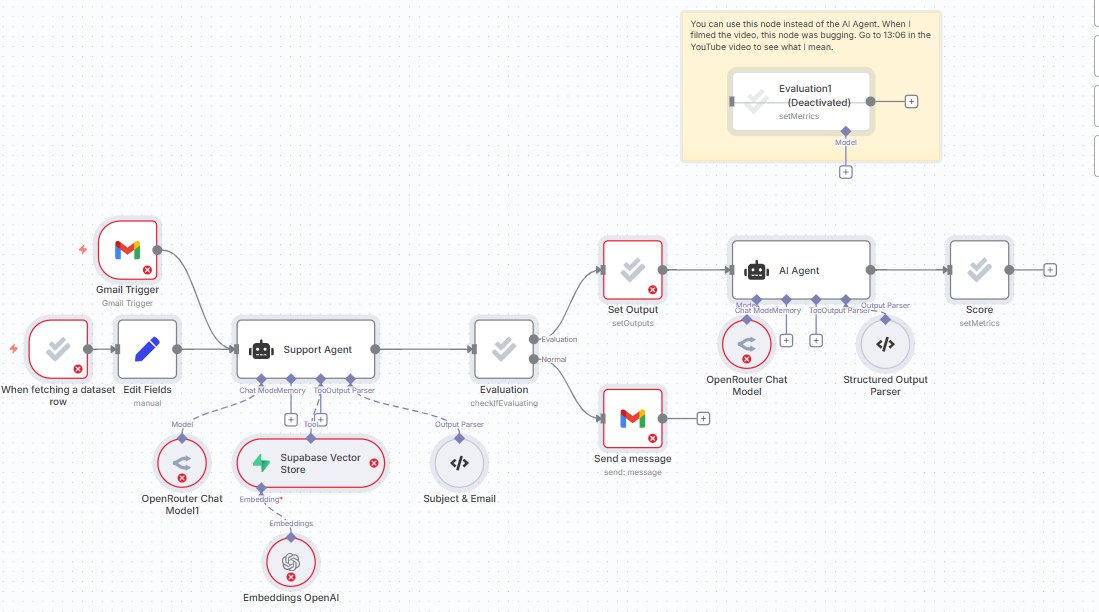
RAG Evaluation System
Sistema de avaliacao automatizada de qualidade RAG. Mede relevancia, groundedness e satisfacao do usuario.
- Relevance Score automatico
- Groundedness check
- HITL feedback loop
- Metricas para dashboard