Workflow Pronto
Workflow com Google Drive, Supabase e Cohere Reranker. Precisao 30-50% maior que RAG simples.
Download Workflow JSON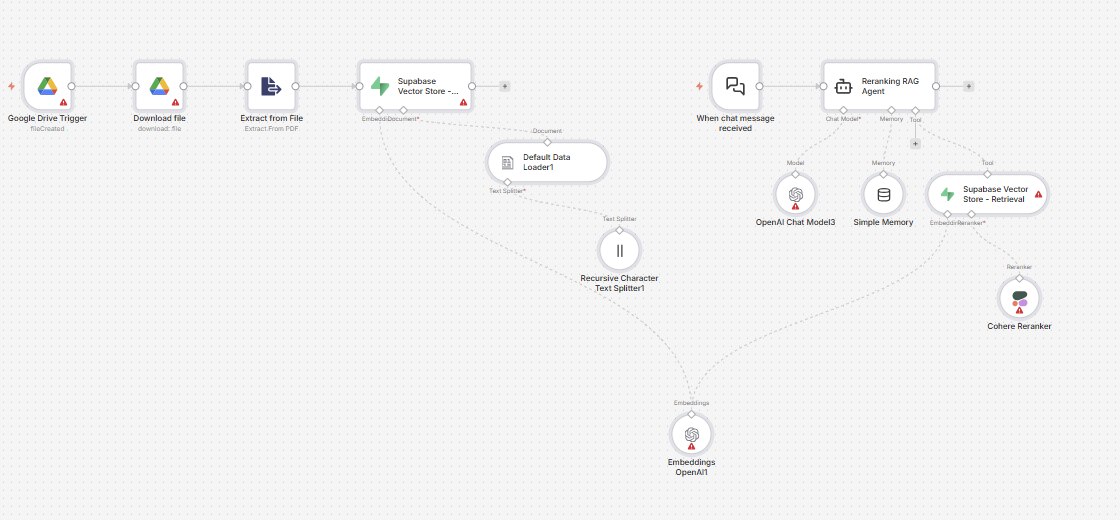
O Que e Re-Ranking?
RAG Simples
Busca os 20 chunks mais proximos semanticamente e usa todos. Pode incluir resultados marginalmente relevantes que poluem o contexto.
RAG com Re-Ranking
Busca 20 chunks, re-rankeia por relevancia REAL usando Cohere, retorna apenas os 10 melhores. Menos ruido, mais precisao.
Fluxo de Ingestao e Vetorizacao
Monitoramento Google Drive
Observa pasta para novos documentos e extrai conteudo de texto automaticamente.
Geracao de Embeddings OpenAI
Converte chunks de documento em vetores usando o modelo de embedding especificado.
Armazenamento Supabase
Faz upload dos chunks embeddados com configuracao de dimensao correspondente.
Fluxo de Re-Ranking e Resposta
Trigger de Chat
Recebe queries via chat nativo do N8N (configuravel para webhook/apps de mensagem).
Busca Semantica Inicial
Puxa os top N chunks (ex: 20) do Supabase baseado em similaridade de embedding.
Re-Ranking Cohere
Processa chunks recuperados atraves do re-ranker Cohere para pontuar relevancia REAL para a query.
Filtragem dos Melhores Resultados
Retorna apenas o subconjunto mais bem rankeado (ex: top 10) para reduzir ruido e melhorar precisao.
Resposta do Agente IA
Alimenta contexto re-rankeado para modelo de chat com janela de memoria de 20 mensagens.
Proposta de Valor
Respostas de Maior Precisao
Re-ranking filtra ruido da busca semantica, retornando chunks verdadeiramente relevantes versus vagamente relacionados.
Eficiencia de Custo
Processa menos tokens eliminando contexto de baixa qualidade, reduzindo custos de API em 30-50%.
Tempos de Resposta Mais Rapidos
Janelas de contexto menores e de maior qualidade significam processamento mais rapido e menor latencia.
Melhor Relacao Sinal-Ruido
Elimina falsos positivos de sobreposicao de palavras-chave em grandes bases de conhecimento.
Compradores Ideais
Gestao de Conhecimento Enterprise
Grandes organizacoes com 10.000+ documentos onde busca semantica retorna muitos matches marginais.
Equipes de Suporte Tecnico
Documentacao de produto com terminologia similar entre features requerendo diferenciacao precisa.
Legal e Compliance
Bases de contratos onde sobreposicao de palavras-chave cria falsos positivos mas precisao de contexto e critica.
Sistemas de Informacao de Saude
Bases medicas onde sintomas/tratamentos similares precisam de desambiguacao precisa.
Plataformas E-Commerce
Catalogos de produtos com descricoes sobrepostas requerendo matching preciso com queries de usuarios.
Bases de Pesquisa Academica
Bibliotecas universitarias precisando de recomendacoes precisas de artigos de arquivos massivos.
Configurando Cohere
1. Crie Conta no Cohere
Acesse o dashboard do Cohere e va para API Keys. Crie uma trial key ou production key.
2. Configure Supabase
Va em Settings > Project Settings > API Keys no Supabase. Crie uma nova API key para conectar com N8N.
3. Mantenha Embeddings Consistentes
Use o MESMO modelo de embedding tanto na ingestao quanto no retrieval. Certifique-se que as dimensoes do Supabase correspondem ao modelo.
4. Ajuste os Parametros
Configure: busca inicial (ex: 20 chunks), retorno apos re-rank (ex: 10 chunks), janela de memoria (20 mensagens padrao).